- English
- Deutsch
- Español
- Français
- Italiano
- Português
PostgreSQL exposes a lot of useful performance data through its system views, but getting that data into a monitoring workflow that runs continuously, alerts on thresholds, and keeps history takes work to build from scratch. Most teams end up with a mix of manual psql queries, cron jobs, and dashboards that cover some of it but not all of it at once.
PRTG uses the PostgreSQL sensor to execute the SQL queries you write against your database on a schedule you define. Query results map to dedicated monitoring channels with individual thresholds, historical graphs, and alert routing through your existing notification setup. Beyond custom queries, PRTG also tracks checkpoint activity, WAL file generation, autovacuum data, and buffer cache hit ratios out of the box. Supported environments: PostgreSQL 7.x and later, Amazon RDS PostgreSQL, Azure Database for PostgreSQL, and self-managed Postgres servers on Linux and Windows.

Slow queries kill application performance. When your Postgres database starts lagging and you don't have query-level visibility, you're troubleshooting blind: hunting through PostgreSQL logs while users are already reporting slow response times, with no fast way to know which query is actually the problem.
Write custom SQL queries pulling from pg_stat_statements, pg_stat_activity, or pg_stat_database, and PRTG takes it from there. Runs them on whatever schedule you set.
You decide which metrics matter: execution time, number of rows returned, buffer reads, custom performance indicators. When query execution crosses your thresholds you get notified before users start complaining, which is the whole point.
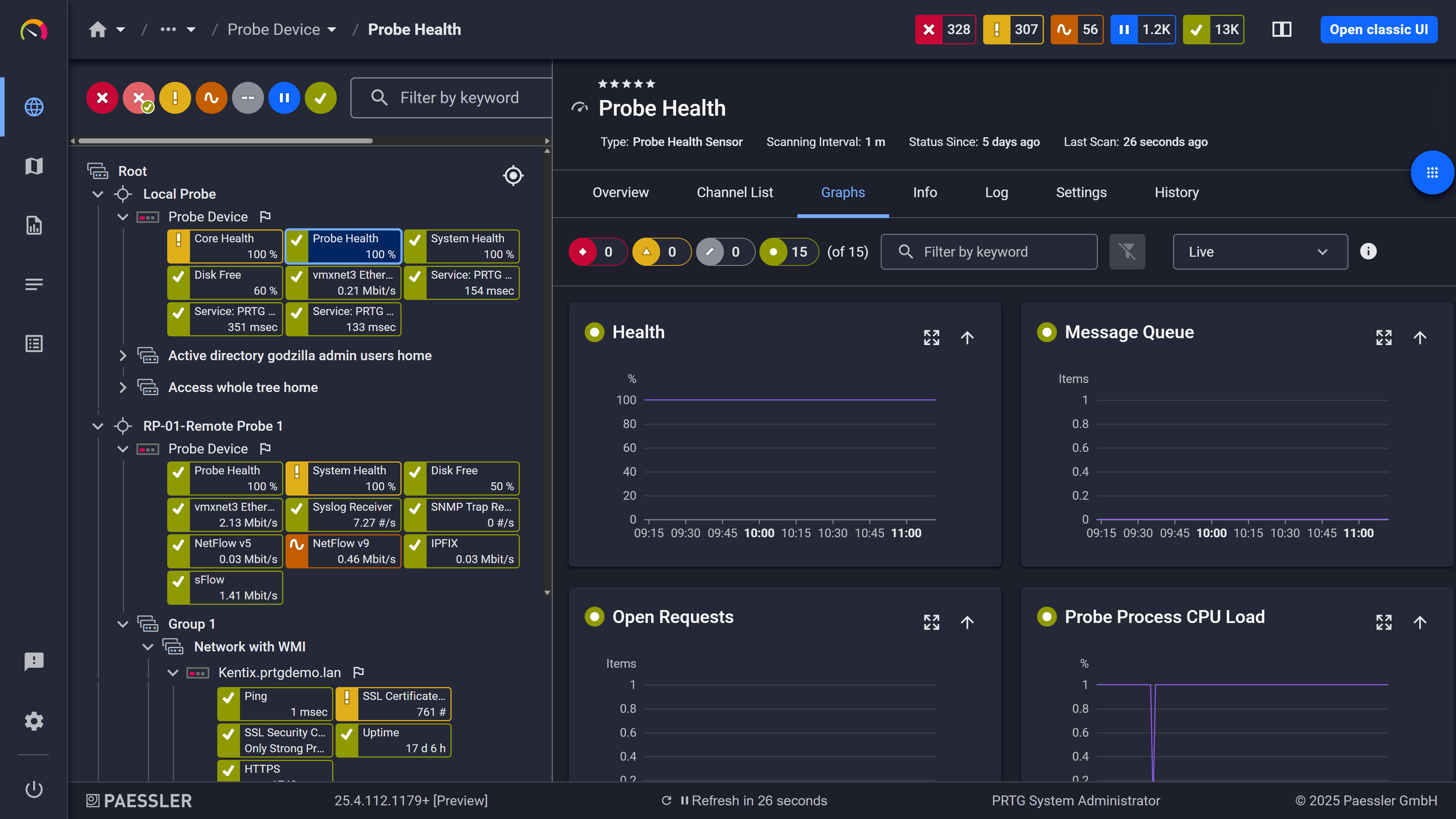
Live graphs, real-time performance data
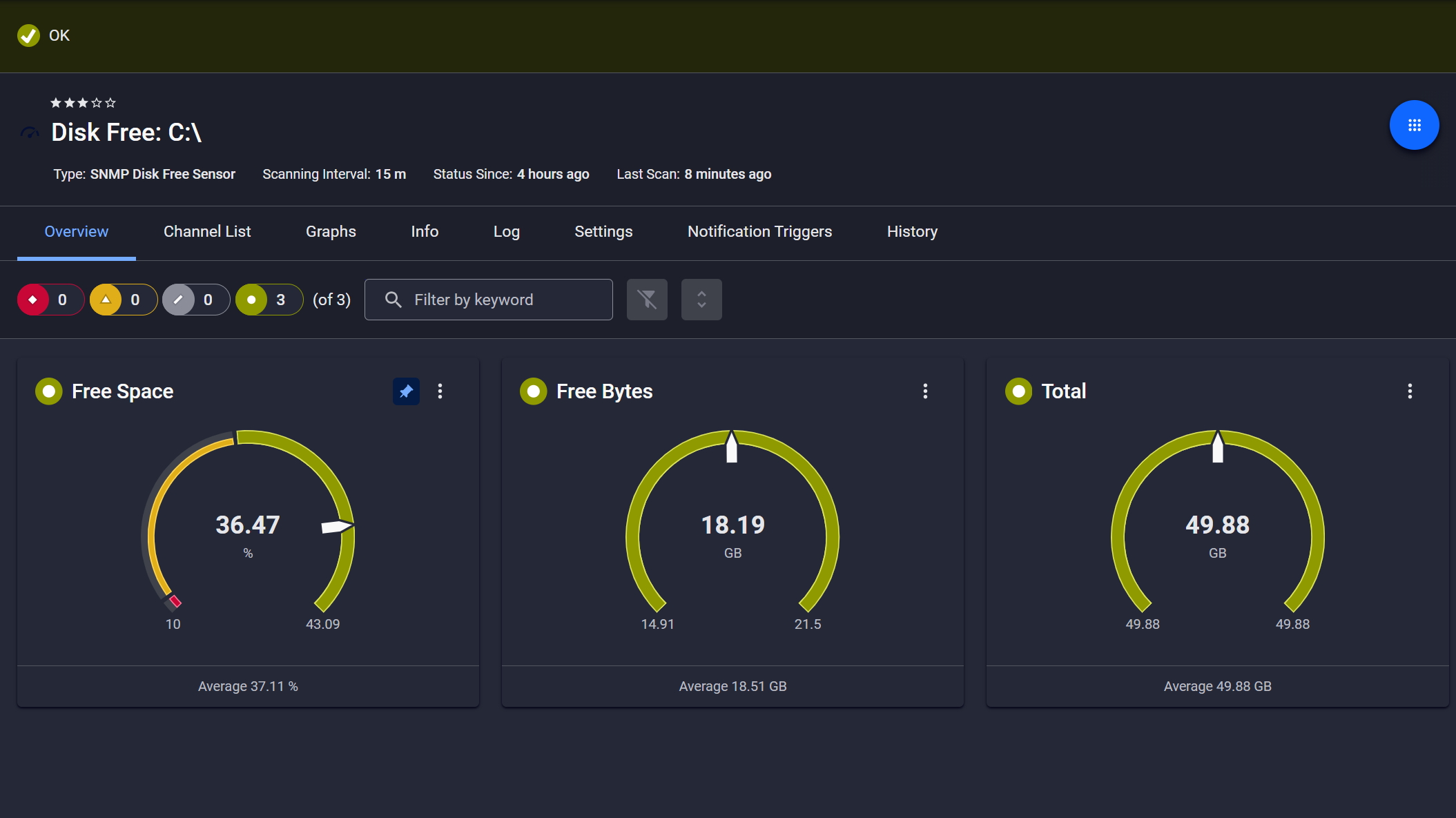
Disk space monitored, alerts ready
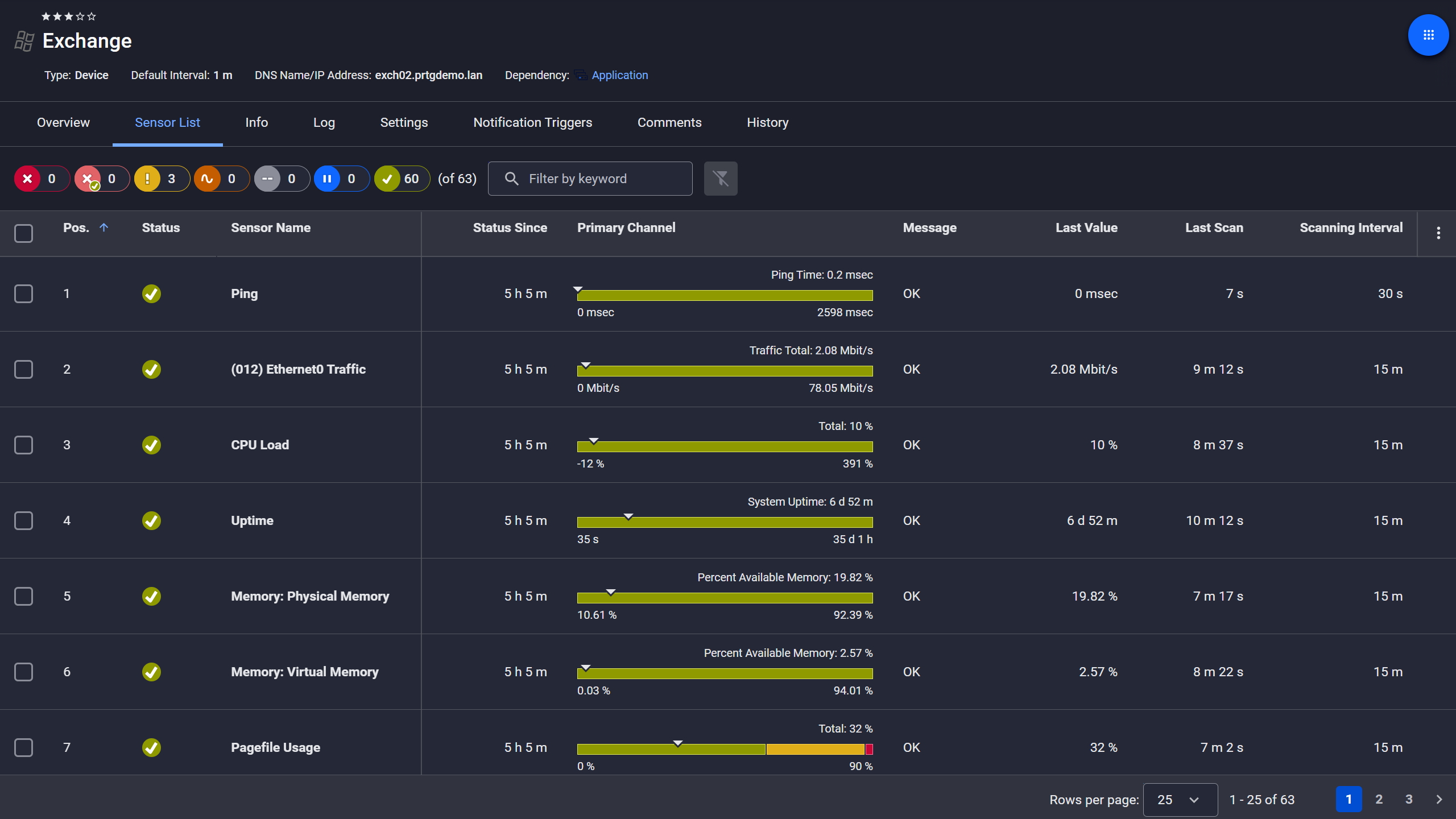
Exchange server, fully under control
A standby server that's quietly falling behind doesn't announce itself. Replication lag builds, WAL shipping stalls, and you find out when failover doesn't work the way you expected. By then it's not a monitoring gap anymore, it's an incident.
When you monitor PostgreSQL with PRTG you can query replication-specific metrics directly: replication lag, standby server status, WAL file counts. Custom SQL queries pull from PostgreSQL system views. You can see exactly how far behind your replicas are running, and also whether your backup systems are actually ready to take over when needed.
Start monitoring your infrastructure in minutes. No professional services, no complex configuration, no risk.
Generic server monitoring will catch a CPU spike. What it won't tell you is whether that came from a runaway vacuum job, a query doing a full sequential scan, or something in your connection pool. The resource problem is visible. The cause isn't.
You write SQL queries, including custom functions, against PostgreSQL system catalogs and performance views. PRTG executes them to track resource metrics. Buffer cache hit ratios show memory efficiency. Checkpoint activity and backend processes reveal workload patterns. pg_stat_database gives you transactions committed, blocks read, tuple activity. Database-aware resource monitoring, not just server-level stats, and that distinction matters when you're trying to isolate what's actually driving the issue.
Tickets keep your team aligned
Scheduled reports, always on time
Probe health at a glance
When Postgres slows down, the database is usually not the whole story. Could be disk I/O, could be network, could be something upstream in your infrastructure. If your PostgreSQL monitoring sits in one tool and your server metrics sit in another you're already spending time you don't have just switching contexts.
PRTG puts both in the same place. Query times, server CPU, disk latency, replication delays: pull them into a single dashboard and look at them together. Correlating a slow query spike with a disk saturation event takes seconds instead of the kind of investigation that involves three browser tabs and a spreadsheet. That's often where the actual answer shows up.This is a bullet point
PRTG uses the PostgreSQL sensor to execute custom SQL queries and track the results. You write the queries that matter to your environment: performance metrics, replication status, table statistics. PRTG runs them on your defined schedule and turns query results into monitored channels with alerts and historical tracking.
Feature | Without PRTG Without PRTG | With PRTG With PRTG |
|---|---|---|
Data Collection | Without PRTG Log into each PostgreSQL server individually, run psql commands to query pg_stat views, export results to spreadsheets | With PRTG Automated SQL query execution on schedule, results in real-time dashboards with historical trends |
Alerting | Without PRTG Set up cron jobs or scheduled tasks to run SQL scripts and parse output files for alert conditions | With PRTG Custom alert thresholds on any query result, immediate notifications via email, SMS, Teams, Slack, or push notification |
Infrastructure Correlation | Without PRTG Switch between database query results and separate server monitoring tools to correlate metrics. This is the one that gets expensive in time. | With PRTG Unified database monitoring and infrastructure monitoring in one pane of glass. PostgreSQL performance, server resources, network metrics, and infrastructure health in one platform |
Query Performance Tracking | Without PRTG Manually review pg_stat_statements output and compare execution times over days or weeks | With PRTG Continuous tracking of query execution time with historical graphs and threshold-based alerting |
Replication Monitoring | Without PRTG Query pg_stat_replication manually, calculate time differences | With PRTG Automated replication lag monitoring with alerts when standby servers fall behind defined thresholds |
Choose the PRTG Network Monitor subscription that's best for you.
| License Name | License description | Price | License Details | Get started | Pricing Details | |
|---|---|---|---|---|---|---|
| PRTG 500 | $200 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 50 devices | ||
| PRTG 1000 | $358 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 100 devices | ||
| PRTG 2500 | $742 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 250 devices | ||
| PRTG 5000 | $1,300 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 500 devices | ||
| PRTG 10000 | $1,642 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 1000 devices |

Anything you can query via SQL, which in practice is most of what Postgres exposes. The common ones: active connections and running queries from pg_stat_activity, transaction and block stats from pg_stat_database, query-level performance data from pg_stat_statements. Replication lag, autovacuum activity, checkpoint stats, cache hit ratios, table sizes. The sensor runs your SQL query and you map result columns to up to 10 monitoring channels. Basically if you can write a SELECT for it, PRTG can track it.
Yes, as long as the instance is reachable over the network. Amazon RDS PostgreSQL, Azure Database for PostgreSQL, both work. You need connectivity from the PRTG probe to the database endpoint and credentials with the right permissions on the views you're querying.
One thing worth being clear about: cloud-specific management features like RDS Performance Insights or automated backup status come from the cloud provider's management API, not from PostgreSQL itself. For those metrics, use PRTG's dedicated AWS or Azure sensors. Core PostgreSQL database performance monitoring works the same whether on-premises or cloud-hosted.
Three timing metrics come built in: total execution time from connection open to close, query execution time for just the SQL itself, and rows affected. That split is useful because a slow total with a fast query execution time usually points to connection overhead, not the query.
For deeper analysis you'll want pg_stat_statements. Write a SQL query against it to pull average execution times, call counts, rows returned, buffer reads. Configure thresholds on what matters for your workload and PRTG handles the alerting from there.
Yes. pg_stat_replication is where most of this lives: replication lag, standby server status, WAL sender processes, replication slot activity. Write a query against it and configure PRTG to run it on schedule. You'll see how far behind your standby servers are, can monitor WAL file generation rates, and get alerts when delays exceed your RPO thresholds.
PRTG's distributed probe architecture lets you watch both primary and standby instances at the same time, even across different geographic locations. That part tends to matter more than people expect.
.NET Framework 4.7.2 or later on the probe system. PostgreSQL Version 7.x or later on the database server.
SQL scripts go in the \Custom Sensors\sql\postgresql subfolder of the PRTG program directory.
You also need Postgres credentials with SELECT permissions on the views you're querying: typically pg_stat_activity, pg_stat_database, pg_stat_statements. And network connectivity between probe and database server. That's it.
The PostgreSQL sensor has a high performance impact compared to simpler PRTG sensors. We recommend no more than 200 PostgreSQL sensors per probe.
Query complexity is what actually determines the overhead. A simple SELECT against pg_stat_activity barely registers. A query that aggregates across large tables will consume real database resources, and that's worth factoring into your interval settings. You control how often PRTG executes queries, so for production systems start conservatively: 5-10 minute intervals, then tighten once you've seen the actual impact.
Network Monitoring Software – Version 26.1.116.1532 (February 9th, 2026)
Download for Windows and cloud-based version PRTG Hosted Monitor available
English, German, Spanish, French, Portuguese, Dutch, Russian, Japanese, and Simplified Chinese
Network devices, bandwidth, servers, applications, virtual environments, remote systems, IoT, and more
Choose the PRTG Network Monitor subscription that's best for you


