
HTTP stands for Hypertext Transfer Protocol. It is an application layer, request-response protocol for the web. HTTP has a client-server architecture that enables the reliable transfer of resources between a web application server and a user agent (UA) such as a web browser. UAs include web crawlers, mobile apps, and other software that is used to access web resources.
HTTP was designed to enable easy communication between devices and applications on the web. It defines how requests for content are formatted and transmitted, and how responses are constructed. HTTP transmits content such as text, images, audio, and video using a suite of protocols called Transmission Control Protocol/Internet Protocol (TCP/IP).
As HTTP has evolved, each version has added new features and each performs some processes, like managing connections, differently.
Tim Berners-Lee, credited as being the founder of the web, wrote the first version of HTTP. The specifications for HTTP, Hypertext Markup Language (HTML), and Uniform Resource Identifier (URI) were written between 1989 and 1990. The first web server went live in 1991.
An internet protocol is a set of rules that defines how devices on an internet network communicate. This set of rules is based on common standards that are created by request for comments (RFCs). RFCs are the building blocks for the standards that are used in network communication on the internet. RFCs are managed by the Internet Engineering Task Force (IETF), the main standards-setting body for the way the internet works. Examples of common network protocols include HTTP, TCP, IP, FTP, and Secure Shell (SSH).
Network protocols can be broken down further. The Open Systems Interconnection (OSI) model is a conceptual framework that describes the functions of a computing system. It consists of seven layers: physical, data link, network, transport, session, presentation, and application. Data in each layer is managed by different protocols. HTTP is a layer 7 (application) protocol, not to be confused with the network layer of the OSI model.
Data on the internet is managed and transmitted by a stack of network protocols that are collectively referred to as TCP/IP. Each layer in the stack can be mapped to layers in the OSI model and each has a different function. HTTP is part of the application layer and allows different applications to communicate with one another. It uses TCP to establish sessions between a client and a server. TCP is part of the transport layer in the stack. It divides messages into data packets at their source which are then reassembled at their destination. IP in the acronym TCP/IP is the protocol that directs packets of data to a specific computer via an IP address. IP is part of the network layer in the stack.
Theoretically, HTTP could use an alternative transport layer protocol to TCP, like UDP, but HTTP almost always uses TCP, which is connection-based and more reliable than UDP. It is favored by applications where the data must be reliable, relevant, and complete, for example a news story. UDP is a connectionless protocol and cannot retransmit lost data packets. However, UDP is faster than TCP and is often used in applications like video conferencing and streaming where small transfer hiccups are barely noticeable. However, the most recent draft version of HTTP, HTTP/3, addresses some of the issues in TCP and UDP, combining features from two protocols: HTTP/2 and QUIC over UDP. HTTP/3 is also called HTTP-over-QUIC.
QUIC is a network protocol that functions as an alternative to a combination of TCP, Transport Layer Security (TLS), and HTTP/2. It is implemented on top of UDP. QUIC transports HTTP/3 traffic over UDP more quickly and efficiently than older HTTP versions that use TCP. QUIC reduces connection latency, improves congestion control, allows multiplexing without head-of-line blocking, enables forward error correction, and allows connection migration. QUIC is fully encrypted with TLS 1.3 by default. UDP is a connectionless protocol, so one of the main functions of QUIC is to ensure connection reliability by allowing the retransmission of packets, for example.
The first version of HTTP only included the GET request method and had no headers, metadata such as content type, or status codes. Because HTTP/09 did not use headers, only HTML pages (hypertext) could be returned to the client. After a response from the server was received, the client immediately closed the connection. HTTP/09 is, for the most part, deprecated but some popular web servers like nginx still support it.
HTTP/1.0 supported GET and POST methods and added versioning information and status codes. Headers were introduced, which allowed a content type to be specified so that files other than HTML could be transmitted. After a response from the server was received, the client immediately closed the connection. The introduction of headers in HTTP/1.0 made HTTP very extensible.
When a request for a web page is made, the page must be rendered in multiple parts, for example text content and other content like images or videos. Image, video, and audio files have their own URLs, and each file must be requested separately. In HTTP/1, this meant multiple individual requests had to be made to the server and multiple connections had to be initiated. HTTP/1.1 introduced persistent connections and pipelining. A persistent connection is not closed by default after a request is made. Pipelining means successive requests in a transaction can be made by a client without waiting for an answer from the server. Persistent connections and pipelining allowed for hypertext and other files like images to be sent successively from the server to the client over a single connection with reduced latency. HTTP/1.1 also allowed additional methods, like DELETE, PUT, and TRACE. This version introduced caching support, client cookies, encoded transfers, and content negotiation. Content negotiation allowed the server and client to select the most suitable content to exchange in terms of language, encoding, or content type. HTTP/1.1 also made HTTP standardization more consistent and is currently the most widely used HTTP version.
Based on SPDY, HTTP/2 is a deprecated communications protocol developed by Google to reduce web page loading latency and to improve security. It was designed to improve web performance and cut costs as HTTP/1.1 was expensive in terms of its use of CPU resources. HTTP/2 introduced advanced multiplexing, which is the ability to efficiently stream data from multiple resources in a single session using HTTP frames and HTTP streams. This feature was introduced to address HTTP head-of-line blocking issues in HTTP/1.1 and to enable parallel communication over a single TCP connection. HTTP head-of-line blocking refers to the scenario where successive requests in a stream can be blocked if there is a problem with the current request in the queue or if it has not yet been completed.
While HTTP/1.1 requests and responses are in text format, HTTP/2 frames use binary format.
HTTP/2 binary frames break down a message request into separate logical units, like header frames and data frames, each of which is encoded in binary and shares a common HTTP stream ID. An HTTP/2 stream is a single, bidirectional, logical request that comprises multiple frames. In HTTP/2, multiple streams can be sent (multiplexed) over a single TCP connection to a server which then maps the frames by their stream ID and reassembles them into complete HTTP/2 request messages according to a predetermined message priority. Multiplexing allows multiple requests to take place over one connection and the server may also send multiple responses to the client in the same way. This feature prevents head-of-line blocking at the application layer and improves performance.
HTTP/2 also introduced better error handling and flow control, and server push. Server push means the server can send data to the client that was not explicitly requested, for example resources the server intuits may be needed by the client. It will first notify the client what it intends to push and the client may decline.
According to W3Techs, HTTP/2 is used by about 46 percent of websites. It is not compatible with previous HTTP versions.
The third version of HTTP, HTTP/3, is designed to improve the performance of HTTP/2 and addresses some HTTP/2 issues. HTTP/3 uses UDP at the transport layer instead of TCP. Head-of-line blocking at the TCP layer in HTTP/2 is resolved by the use of UDP. TCP head-of-line blocking refers to the scenario where, if a packet is lost, a message is blocked until the packet can be retrieved. HTTP/3 allows faster connections as it does not rely on IP addresses. It uses connection IDs so that downloads are consistent even when there is a network change. Unlike TCP, UDP does not require that a data transfer is confirmed before the next request is transmitted. Connections are also faster because fewer data packets need to be sent over parallel streams. To establish a connection, TCP uses a three-way handshake. UDP creates a connection in one round trip. Because TLS 1.3 is integrated into HTTP/3, it only supports encrypted (HTTPS) connections.
Custom alerts and data visualization let you quickly identify and prevent network health and performance issues.
Headers make HTTP extensible as client and server may agree to add any new field names and information to suit their needs.
Although it can, an HTTP server is not required to store any information between requests. This feature made early HTTP versions stateless. Requests in versions before HTTP/2 were made independently without any knowledge of what happened in previous requests. HTTP was designed as a stateless model mainly for scalability; HTTP requests can be routed to any server because the server does not need to maintain a particular state for a client. This makes it easy to scale the number of servers to match the expected workload where maintaining a persistent connection would be resource intensive. When it is necessary to interact with a website in a progressive way, for example when online shopping, HTTP may use cookies, server-side sessions, URL rewriting, or hidden variables to enable stateful sessions These workarounds are called stateful functions. Another advantage of statelessness is that the amount of data that needs to be transferred in most cases is minimized.
The full TCP/IP stack is not stateless. TCP at the transport layer is stateful, maintaining the state of an HTTP session and ensuring that lost data packets can be retransmitted.
HTTP is generally considered connectionless because, after the client has established a connection with a server, sent a request, and received a response, the connection is immediately dropped. HTTP is also considered connectionless because network connections are controlled at the transport layer, not at the application layer. HTTP uses TCP, which is connection based, at the transport layer.
As long as both the client and the server know how to handle specific data content as specified by the MIME-type in a header, any type of data can be sent via HTTP. MIME stands for Multipurpose Internet Mail Extensions.
HTTP is used on the web wherever data needs to be transferred between a client and server, for example APIs, web services, and browser requests.
HTTP is usually used by users that do not have any confidential information that they have to worry about being hacked, who do not wish to purchase an SSL certificate, or who do not want the complexity of maintaining a secure site.
Early versions of HTTP were stateless but not sessionless. Typically, an HTTP session has three steps, with some variation in how the steps are handled in different versions.
First, the client establishes a connection to the server. In most versions of HTTP, this is a TCP connection, but HTTP/3 uses UDP at the transport layer.
Second, the client sends a request message to view a web page, for example. A request method in the message specifies the action that the server needs to take. For example, to view a web page, the client will use the GET method.
Third, the server processes the request and returns a response message to the client, for example the content of the requested web page if the request was successful, and a status code.
In HTTP versions before HTTP/1.1, the connection was closed after the completion of a request by default. If the client wanted the connection to be kept open, it had to specify that by enabling the Keep-Alive Connection header. HTTP/1.1 and subsequent HTTP versions allow the client to send additional request messages and the connection is kept alive by default. So, if a client receives an error code, it might want to retry the request. If the client wants the connection to be closed, it must be specified with the Close Connection header.
Between the client and server are numerous other servers called proxies, which are intermediaries that perform additional functions like encrypting content, caching and compressing data, load balancing, logging, and providing shared connections for concurrent users.
HTTP messages are exchanged in a MIME-like format. MIME is a standard for internet mail that enables the format of message requests to be extended to support data other than plain ASCII text. MIME-like headers in HTTP have a similar function; for example, they allow a client to select the appropriate application to open files other than text, like video, images, executables, audio, etc.
HTTP requests and HTTP responses use the same message format. Messages consist of a start line (either a request line in the case of a request message or a status line in the case of a response message), one or more optional header fields, an empty line that indicates there are no more header fields, and an optional message body.
The start line includes the protocol version and some information about either the type of request, in the case of a request message, or the success or failure of the request, in the case of a response message.
HTTP headers allow the inclusion of additional information about the request or response such as the request method in the case of request messages and the length of the returned content in the case of response messages.
The optional message body in a request may include the information that needs to be uploaded to or deleted from a server. The optional message body in a response may include the content requested by the client.
The use of headers is what makes HTTP flexible and extensible as a client, and a server may create new headers relevant to a transaction as long as they both agree on the format.
Some HTTP headers are specific to request or response messages, for example the Accept-Language header is specific to request messages. However, some headers may either appear in requests or responses. For example, the Content-Type header, categorized as a representation header, may be included in request or response messages. In the former, it specifies what type of content the client wants. In the latter, it specifies what type of content the server is returning.
Request headers may include additional information about the client and the resource. For example, the Uniform Resource Identifier (URI) is the resource upon which the method needs to act to get information from a specific website, for example. HTTP request headers may also specify information about what data should be cached, general connection information, authentication details, date and time, transfer encoding information, in what format information can be used to transfer content, etc.
Accept request headers – like Accept-language and Accept-encoding – and some complementary representation headers – like Content-Language and Content-Encoding – allow the content negotiation feature of HTTP. The Accept headers specify the client’s preferences and complementary representation headers in the response specify what the server actually returned.
Response headers may include additional information about the server and the resource. They may also specify any cookies, the length of the returned content, the type of content, when the content was last modified, etc.
There are special headers for numerous HTTP functions like authentication, connection types, storing cookies, downloading files, proxy management, security, transfer encoding, etc.
HTTP is a request-response model for network communication. Its counterpart is the publish-subscribe model in which a server (also called a broker) receives and distributes data while the client either publishes data to the server to update it or subscribes to the server to receive information. In the publish-subscribe model, data is automatically exchanged but only when it changes or if the information is new. MQTT is an example of a transport protocol that uses publish-subscribe.
Web Real-Time Communication (WebRTC) is used to perform peer-to-peer (P2P) connections, which allow the easy sharing of application data and media files like audio and video. Facebook Messenger is an example of an application that uses WebRTC.
QUIC uses TCP but is built on top of UDP. QUIC was designed to reduce latency in internet data transfers and to address some HTTP/2 issues. Google Chrome is an example of an application that uses QUIC.
The InterPlanetary File System (IPFS) is a recent alternative to HTTP that has a distributed P2P architecture and allows a choice of TCP, QUIC, or WebRTC connections. With its distributed architecture, it was designed to resolve server failure issues that are common to centralized network communication protocol models like HTTP.

Sensor HTTP Full Web Page
Cloud HTTP monitoring
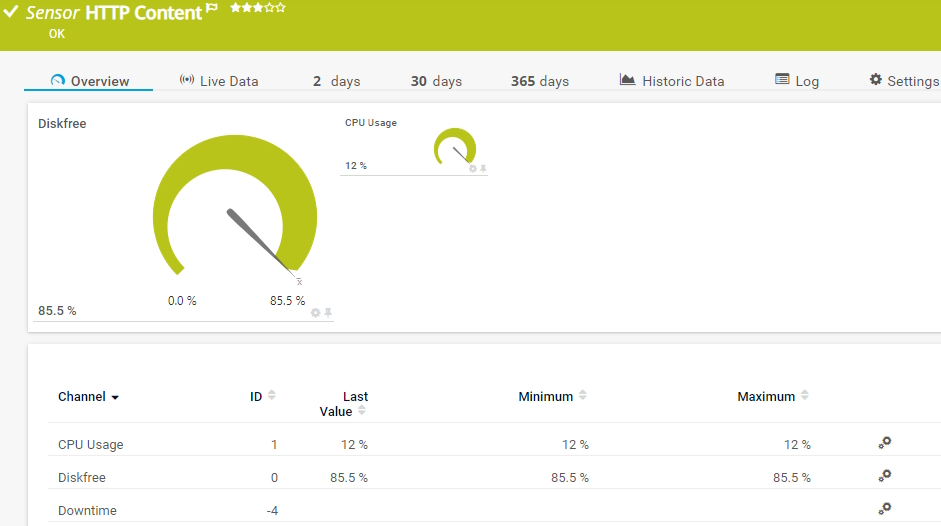
Sensor HTTP Content




Hypertext Transfer Protocol Secure (HTTPS) is basically HTTP with encryption; it “wraps” HTTP messages in an encrypted format. HTTPS uses Transport Layer Security (TLS) to encrypt HTTP requests and responses.
HTTP and HTTPS use different ports. Customarily, HTTP uses port 80 and HTTPS uses port 443 although, in theory, any port can be used except for those that are reserved for specific services.
The primary advantage of using HTTPS is the improved security. For websites that do not transfer confidential information, HTTP could be an acceptable option and less complex to set up and maintain. In addition, in 2014, Google announced that it would be using HTTPS as a lightweight ranking signal to encourage businesses to switch from HTTP to HTTPS.
There are some subtle and, in practice, minor disadvantages in using HTTPS instead of HTTP. First, there may be some extra overhead when transferring data as some handshaking must be done first. Second, the process of generating encryption keys may keep the server from performing other tasks. Third, some content cannot be cached locally because the data is encrypted.
By default, HTTP/3 is only available with HTTPS.
Real-time notifications mean faster troubleshooting so that you can act before more serious issues occur.
TCP is more reliable but is slower than UDP. However, when UDP is combined with QUIC, the result is fast and reliable packet transmission using HTTP/3. HTTP/3 is still in its infancy. As of early 2021, it had been enabled by popular applications like Google, WhatsApp, YouTube, and Facebook, but not by equally popular applications like Uber or Twitter.
HTTP/3 is still an RFC draft but is supported, according to Wikipedia, by nearly 75 percent of web browsers and, according to W3Techs, 21 percent of the top 10 million websites for which W3Techs provides usage data.
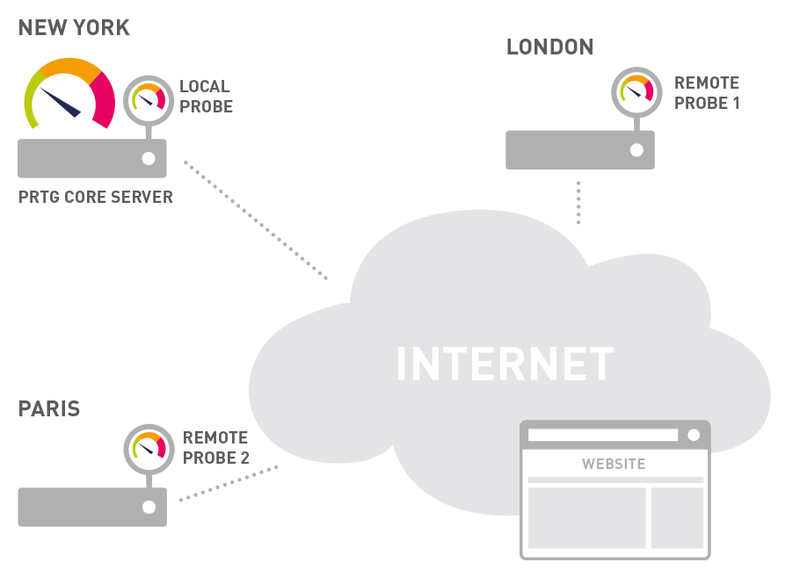
Internet commercialization has resulted in a greater need for real-time network analysis and monitoring to provide organizations with maximum uptime. Packet monitoring and analysis – called packet sniffing – is the key to analyzing which packets are lost, when, and why, in order to maintain high, consistent performance.
PTRG packet sniffing tool monitors and analyzes every packet on your network to identify the bandwidth used, bandwidth hogs, and potential security loopholes. The packet sniffer monitors all HTTP, HTTPS, UDP, and TCP traffic, as well as other mail, file transfer, remote control, and infrastructure traffic.
PTRG web sensors tool allows you to monitor web servers using HTTP to make sure that web pages are always reachable.

