- English
- Deutsch
- Español
- Français
- Italiano
- Português
Server availability monitoring across mixed environments is rarely a single-tool problem. Windows servers need WMI or SNMP, Linux systems work best with SSH or SNMP, and cloud instances require API-based checks via AWS or Azure credentials. Running separate tools per platform is common, but it means your visibility is fragmented exactly when you need a complete picture most.
Paessler PRTG brings those checks into one platform, running continuous availability monitoring over ICMP ping, SNMP, WMI, and HTTP across physical servers, virtual machines, cloud instances, and on-premises systems. When a server stops responding, notifications go out immediately. Auto-discovery keeps pace with infrastructure changes so new servers, VMs, and cloud instances get picked up without manual updates. Supported environments include Windows Server, Linux (RHEL, Ubuntu, CentOS, Debian), VMware ESXi, Microsoft Hyper-V, AWS EC2, and Azure Virtual Machines.

Continuous availability checks mean your team has the information before anyone else does. PRTG runs uptime monitoring using ICMP ping, SNMP uptime sensors, and service status monitoring, and sends notifications immediately via email, SMS, or push when a server stops responding. Your IT teams have enough lead time to start troubleshooting and resolve issues before downtime reaches anyone outside the building.
What PRTG provides:
Separate server monitoring tools for Windows, Linux, and cloud instances don't just add overhead. They create gaps. When something breaks your team is toggling between dashboards correlating data instead of actually fixing anything.
One platform. SNMP for Linux and network devices, WMI for Windows, SSH when you need agent-free Linux coverage, HTTP/HTTPS for web servers and APIs. All of it lands in a single infrastructure monitoring view showing server availability, performance metrics, and resource utilization across your environment. Also remote probes extend that coverage to branch offices and multi-site setups without opening inbound firewall exceptions, which is worth knowing upfront.
What PRTG provides:
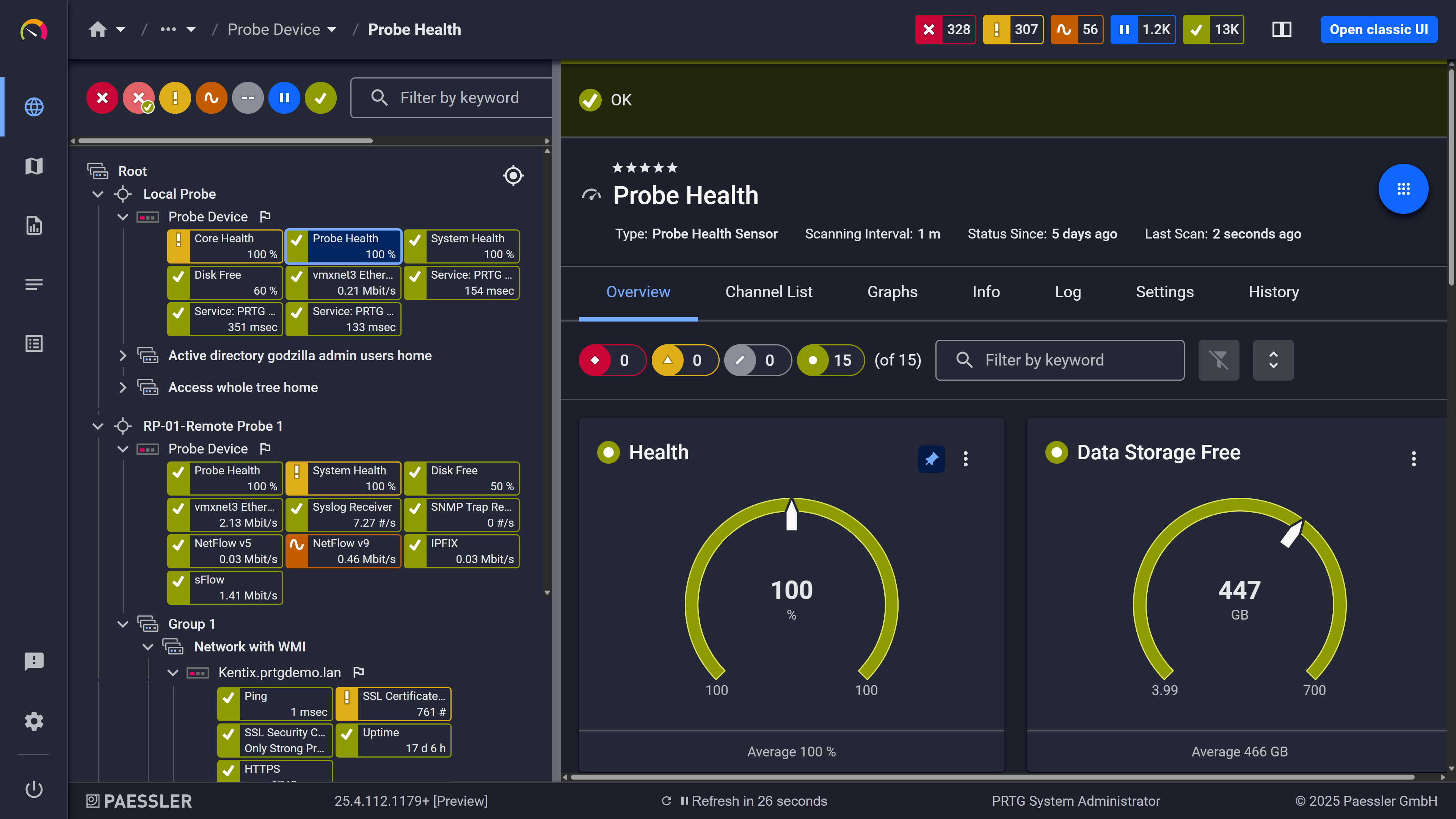
Probe health at a glance
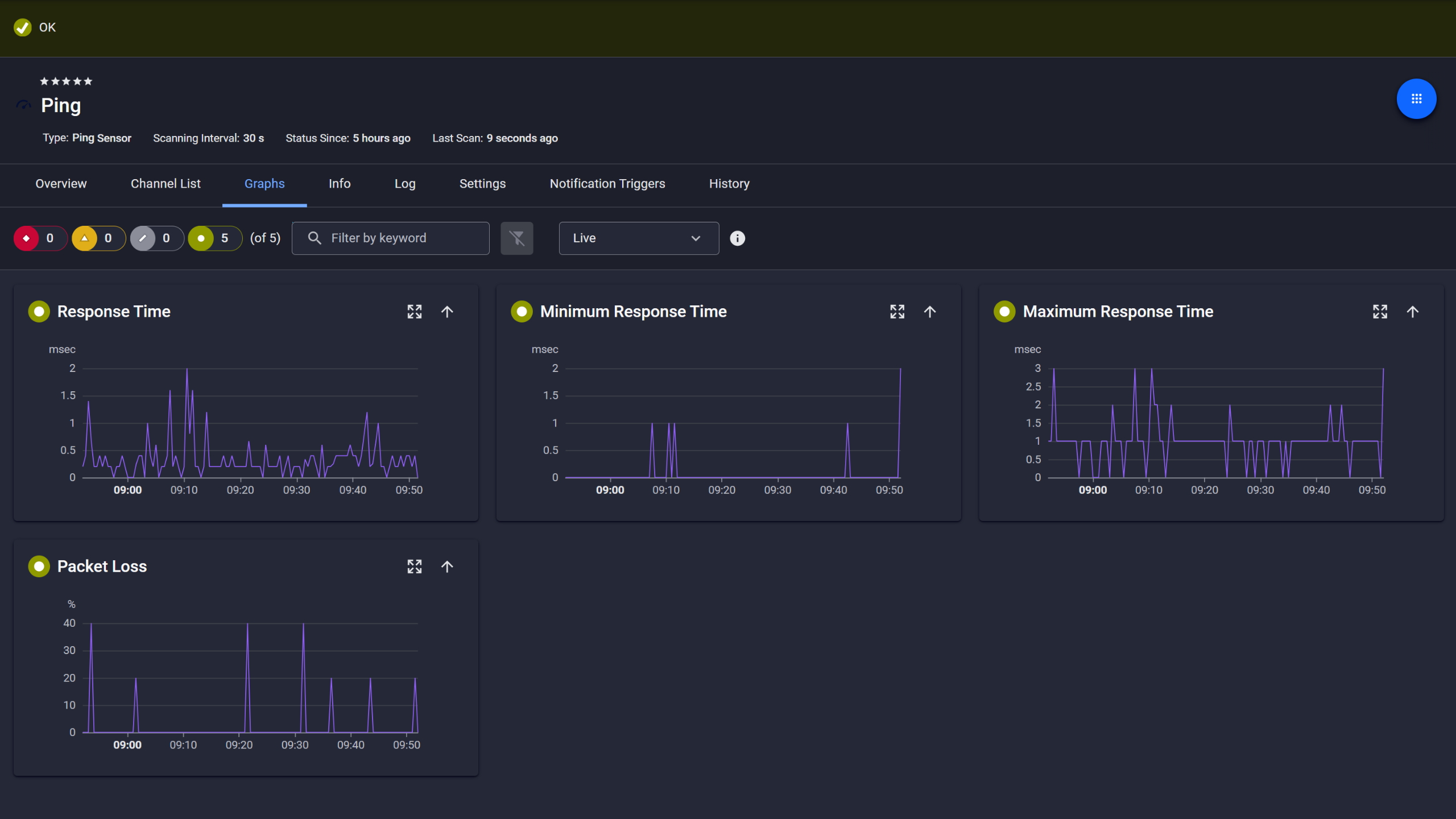
Ping response and packet loss
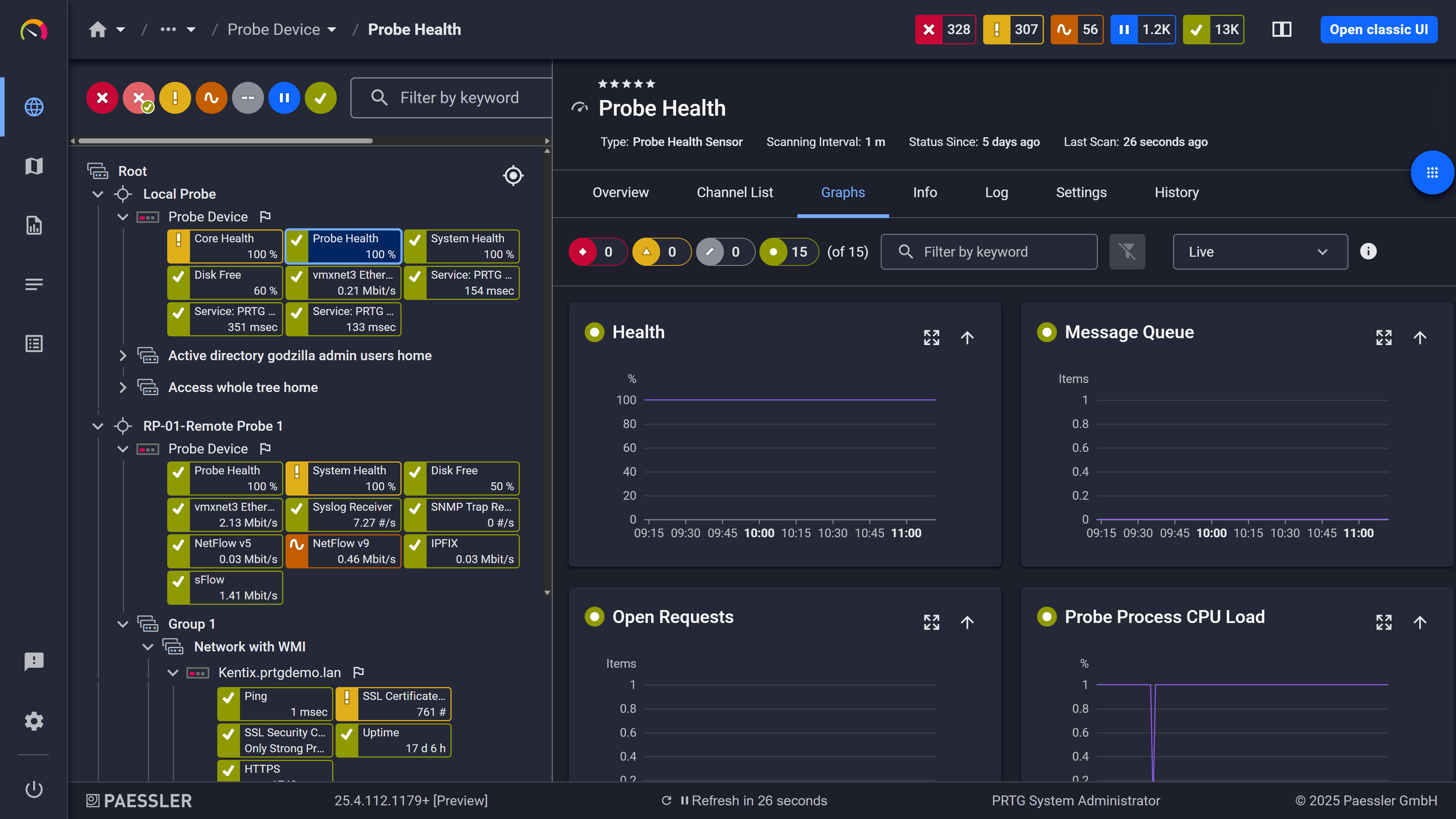
Live graphs, real-time performance data
When an auditor asks for uptime documentation, the answer shouldn't involve spreadsheets and manual log exports. That's a data problem, not a reporting problem.
PRTG retains historical availability data automatically. Outage duration, recovery times, uptime percentages, all of it stored without anyone having to remember to export anything. The PRTG SLA Reporter (an extension you can add separately) turns that into structured compliance reports covering MTBF and MTTR. Ready for audits or stakeholder reviews, no assembly required.
What PRTG provides:
Start monitoring your infrastructure in minutes. No professional services, no complex configuration, no risk.
New servers deploy. VMs spin up. Cloud instances scale out overnight. Manual monitoring configuration doesn't keep pace and the gaps don't show up until an incident reveals what wasn't being watched.
PRTG's auto-discovery scans network ranges continuously. New Windows, Linux, VMware, or cloud-based servers get detected and assigned preconfigured sensors automatically. With 250+ sensor types and device templates, new infrastructure is in server monitoring within minutes. Not a day later after someone remembers to add it.
What PRTG provides:
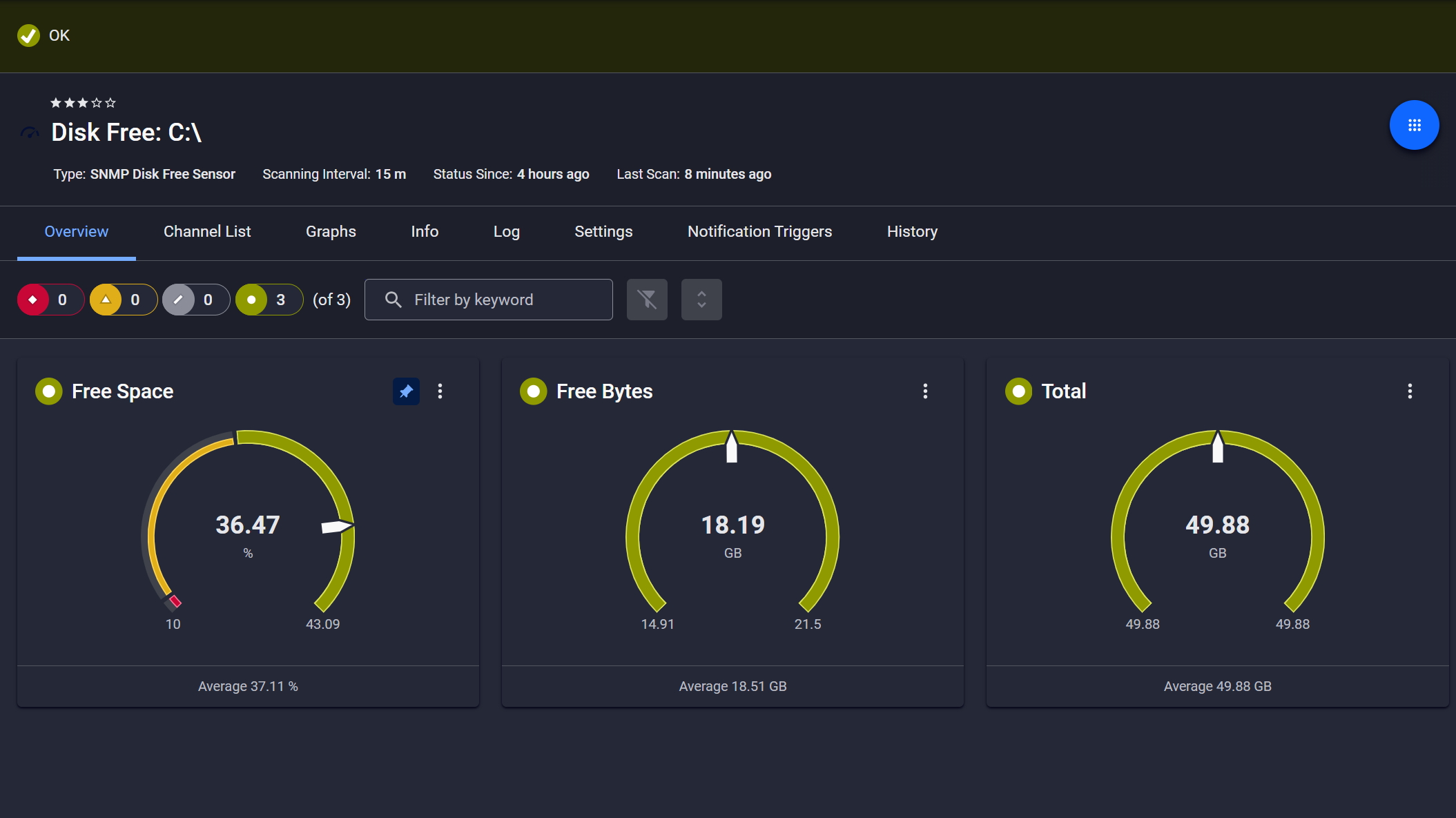
Disk space monitored, alerts ready
Scheduled reports, always on time
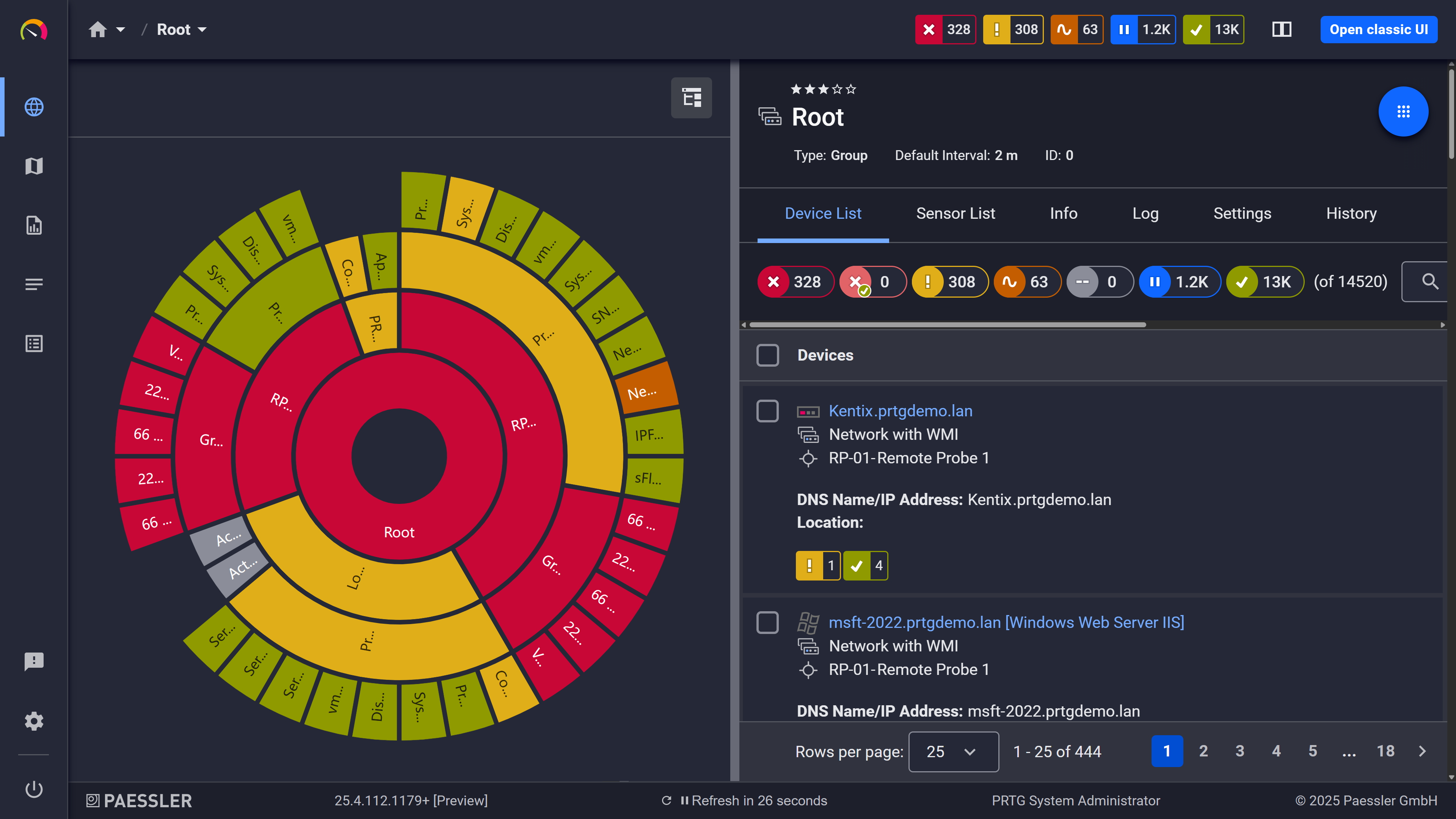
PRTG sunburst chart visualizing the full network hierarchy with color-coded sensor status
Servers give you signals before anything breaks. CPU utilization climbs, disk space fills, memory pressure builds, latency creeps up. PRTG's threshold-based alerts fire when key metrics approach critical levels, giving your team time to act on what the data is already showing. Thresholds are configured per sensor, so alert sensitivity matches the actual requirements of each system. And when upstream failures cascade, dependency mapping keeps the alert queue focused on the actual bottleneck rather than everything downstream from it.
What PRTG provides:
PRTG's server monitoring uses multiple methods to track server uptime, health, and performance across diverse server environments. Here's how continuous visibility works in practice.
FEATURE | Manual Approach Manual Approach | With PRTG With PRTG |
|---|---|---|
Manual Approach Check servers individually via ping, login attempts, or wait for user reports | With PRTG Automated availability checks every 60 seconds (or faster) across all servers with instant notifications | |
Multi-Platform Coverage | Manual Approach Use different server monitoring tools for Windows (Event Viewer, PowerShell), Linux (command-line scripts, Nagios), cloud (AWS CloudWatch, Azure Monitor) | With PRTG Single monitoring solution for Windows, Linux, VMware, AWS, Azure, on-premises, and cloud-based servers using SNMP, WMI, SSH, HTTP |
Uptime Tracking & SLA Reporting | Manual Approach Manually log outages, calculate uptime percentages in spreadsheets, export logs from multiple sources | With PRTG Automated historical data collection with PRTG SLA Reporter (extension you can add) generating compliance reports (MTBF, MTTR, uptime %) |
Proactive Issue Detection | Manual Approach Wait for crashes, performance complaints, or periodic manual checks to discover server issues | With PRTG Threshold-based alerts notify IT teams when CPU, disk, memory, or latency approach critical levels before failures occur |
Centralized Visibility | Manual Approach Log into each server individually, check multiple dashboards, correlate data manually across tools | With PRTG Single dashboard shows server health, uptime, performance metrics, and resource usage across entire infrastructure |
Choose the PRTG Network Monitor subscription that's best for you.
| License Name | License description | Price | License Details | Get started | Pricing Details | |
|---|---|---|---|---|---|---|
| PRTG 500 | $200 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 50 devices | ||
| PRTG 1000 | $358 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 100 devices | ||
| PRTG 2500 | $742 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 250 devices | ||
| PRTG 5000 | $1,300 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 500 devices | ||
| PRTG 10000 | $1,642 | per month paid annually | Buy nowBuy now | Enough to monitor multiple aspects of 1000 devices |

Uptime monitoring tells you whether a server is online, responding, and actually reachable. PRTG's server monitoring runs those checks using ICMP ping, SNMP uptime sensors, WMI system checks, SSH monitoring, and HTTP/HTTPS probes.
People mix this up with performance monitoring but they're not the same thing. Availability is "is it up." Performance is the harder question, CPU usage, disk I/O, memory pressure, latency, response time. A server can be reachable and still be too degraded to matter to the application running on it.
Physical servers, virtual servers (e.g. VMware ESXi and Hyper-V VMs), AWS and Azure cloud instances, web servers (Apache, IIS, NGINX), database servers (SQL Server, MySQL, Oracle), application servers, file servers, mail servers. Windows Server and Linux across the main distributions plus Unix variants.
Protocol-wise SNMP handles cross-platform coverage, WMI goes deeper into Windows-specific metrics, SSH covers Linux without an agent. Most of that works without installing server monitoring software on the monitored system, which matters when you're looking at hundreds of servers.
ICMP ping checks basic network reachability. TCP port monitoring goes further and confirms whether critical services are actually listening, because a server can respond to ping while the service on it is completely dead. SNMP uptime sensors query device status directly. WMI sensors watch Windows service states.
Notifications go out via email, SMS, push, or different webhookswhen something goes unresponsive. Also worth understanding how dependency mapping fits in here: if a switch fails and takes 50 servers offline PRTG sends one alert for the switch. Working through 50 simultaneous server alerts to find the actual cause is exactly the situation dependency mapping exists to prevent.
Yes. EC2 instances, RDS databases, Elastic Load Balancers on AWS. Virtual Machines, SQL Database, App Services on Azure. Native cloud sensors plus standard protocols depending on what the instance supports.
Remote probes can run inside the cloud network or from on-premises. Hybrid setups land in the same view, physical servers, VMware VMs, cloud instances together. One thing worth flagging upfront: native GCP sensors aren't available out-of-the-box, so Google Cloud coverage needs a different approach.
Availability is one question: is the server up and reachable. Ping, uptime checks, service status sensors answer it.
Server Performance is what comes after. CPU, disk space, disk I/O, memory, bandwidth, latency, response time. That's where bottlenecks develop before availability becomes the problem. PRTG does both from the same platform, which means when a performance issue escalates into an outage you're not switching tools mid-incident to figure out what happened.
For most environments no. SNMP, WMI, SSH, and HTTP/HTTPS are already active on the systems you want to monitor. SNMP for Linux and hardware, WMI for Windows and Active Directory, SSH for log checks and custom scripts, HTTP/HTTPS for web servers and APIs. Nothing to install on the monitored server.
Remote probes handle distributed environments where you need collectors closer to the monitored segment. They don't sit on individual servers, they collect from a network location. Worth knowing if you're managing a large environment where deploying agents across everything isn't realistic.
Yes. Deploy probes where the servers are: datacenter, branch office, AWS VPC, Azure virtual network. Everything reports back to one PRTG core server.
Server availability, performance metrics, resource usage across physical, virtual, and cloud in one place. No exporting data between server monitoring tools, no switching dashboards per environment to get a complete picture.
Network Monitoring Software – Version 26.1.116.1532 (February 9th, 2026)
Download for Windows and cloud-based version PRTG Hosted Monitor available
English, German, Spanish, French, Portuguese, Dutch, Russian, Japanese, and Simplified Chinese
Network devices, bandwidth, servers, applications, virtual environments, remote systems, IoT, and more
Choose the PRTG Network Monitor subscription that's best for you


