
Surf the wave as it comes
When Startups grow – and the it gets stuck
It’s every founder’s dream: the numbers soar right after a startup hits the market. Media is reporting on it, the service is recommended left and right in the social web.
But in reality, sudden growth often has a dark side: the euphoria that accompanies a successful beginning turns into sleepless nights as the startup’s IT begins to collapse. The server buckles, downloads take forever, the login gets stuck. The longer the outage, the higher the costs. An established company might be able to stomach it, but a startup definitely can’t!
It’s actually similar to surfing: you wait in the water for ages before it comes – the perfect wave! But it’s too big for a startup. Founders have to ask themselves: How do I stay productive so that I can ride the wave for as long as possible?


Established Companies
VS.
Internet Startups
Customer rushes are often managed by the marketing department – the company is prepared
Rush
Rushes are usually not controlled and result from short term market changes
Growth occurred over a period of several years, company had time to adjust
Growth
Growth occurs within hours – company must react immediately
Customer confidence has been built up over years – a failure isn’t as serious
Trust
Has not yet had time to build up customer confidence – a failure threatens to make company lose potential customers forever
Often offer material products, which function offline for a time as well
Products
Many startups as well as established internet companies offer web based services – every minute of a failure means a loss in revenue
Often have all important IT services in-house. This is expensive but carries less risk. Often use too many monitoring systems - should reduce complexity.
Established IT infrastructure ensures reliability. Customers might not even notice if a failure occurs.
IT
Often use various external services like cloud services to save on costs – and somehow have to keep tabs on everything during a rush.
Often forget monitoring – and cannot determine where exactly a problem occurs.
Budget is too low to allow for redundant structures. Users are usually directly affected if a failure occurs.


“Monitoring makes every Startup more capable of acting”
Mathias Hengl is a PRTG developer and monitoring expert at Paessler AG. He explains in an interview where failures might occur – and explains why especially lean-Startups should attend to monitoring.
A startup receives a visitor onslaught in just a few hours. How should the IT team react?
Mathias Hengl: Every normal user rush has a fast-rising curve and goes through various system phases over a period of time, contrary to DoS attacks. There’s an early time window where you can see that a capacity overload will occur soon, but the users don’t yet notice anything. Then comes a phase where the users notice that the system is slow, but user transactions can still be executed. The website might be a little slower for the user, but everything is still working.
In order to respond immediately, one has to know what happened, and where – hopefully before the users find out. If I notice that my system is going to be overloaded half an hour before the users notice, I can easily take countermeasures without noticeable downtime.
What good is half an hour?
Mathias Hengl: If I know the source of the problem, I can react to the situation directly. For example, we recently had a case where we decided to shut off the website compression. By doing this we were able to free up CPU on the web server and avert imminent down time.
This fast reaction increased the time window available to counteract the problem – for example, by connecting an additional web server or by having queries from a different country be processed by a local web server.
In order to do this, though, you have to know where the problem lies as early as possible; otherwise you end up chasing after the problem, which can create more problems: I quickly add another webserver – and then my database crashes. Searching for errors takes time – which ultimately costs revenue. The more relevant information I have, the faster and more efficiently I can react.
And if I don’t find a fast solution on the technical level and downtime isn’t avoidable?
Mathias Hengl: Then you still have the option of actively communicating with your users. Use Facebook and Twitter to communicate that you’re currently experiencing difficulties and things might be a bit slow. Most customers are understanding. They are quicker to be upset if they don’t know what is going on.
In this respect, a monitoring system is the foundation for effective and meaningful communication. It’s also important to not be too vague with the communication. Just saying that the site or system is down doesn’t usually satisfy customers. If you can say instead that there is an issue with the database, you are communicating to your customers that you aren’t searching blindly for solutions, but that you are actively addressing the problem.
“A Monitoring system is the foundation for effective and meaningful communication.”
Where could the IT system fail?
Mathias Hengl: An IT system is comparable to an onion. An onion consists of several layers, where each layer is separated by a thin skin, comparable to network and firewall components. There are usually four layers: the access layer with internet/provider connection, name resolution and load balancing, the web delivery layer with the web or application server, the processing layer in which processes and housekeeping activities are executed and the data management layer with databases or files.
Overloading can occur between each of the layers. If I have millions of small queries, my provider might not be able to handle them all. Or I might have a large bandwidth but my network card is maxed out by the number of queries. Or so many orders come in that the instances aren’t able to keep up with the checks. This can lead to real catastrophes – the user gets the ‘OK’ that the process is complete, but the data management isn’t able to keep up with the incoming information and important data gets lost.
Every startup should know where its weaknesses lie and what might lead to a failure.
Many startups work with external service providers, like cloud providers. They must have established monitoring systems, right?
Mathias Hengl: That’s right. Many startups work with external service providers and rely on their partners. The founders have enough other things to do. They want their product to become established on the market and work on their business model. Unfortunately, service provider systems fail sometimes, too. We recently had a case where the cloud systems as well as the cloud provider’s monitoring failed due to overloading.
This is like blind flying for a startup. This is especially bitter if it occurs in a crucial phase. Startups usually have more than one partner and therefore don’t have one specific monitoring system, but in order to act efficiently, you should have all your information in one place.
Besides, the technical partner might claim that there are no problems on his side. In that case, you’re pretty well trapped and can hardly argue if you don’t have your own data. In contrast, if you’ve set up your own monitoring, you just have to send your technical partner a diagram with monitoring results and ask what is going on. That’s why monitoring is a useful tool for communicating on partner level as well.
“Without knowledge of the actual situation, I cannot react. And that requires data.”
What problems could arise with cloud services?
Mathias Hengl: The cloud gives startups the impression of security. However, even cloud services can have problems. For example, a machine crashes and no new machine is started. As cloud resources are often shared, load peaks are reached more often. Security holes may arise and cloud snapshots could get deleted by a third party. Of course, these are the exceptions, but they do come up again and again. You can’t just pretend they don’t exist.
To say it plainly: there is definitely nothing wrong with working together with a cloud provider. The important thing is to ensure that you are always 100% capable of acting.
Lean startups survive because of their ability to act flexibly. Isn’t professional monitoring a little oversized? Doesn’t it weigh down the startup?
Mathias Hengl: It actually does the opposite. Professional monitoring makes every startup more capable of acting. Without knowledge of the actual situation, I cannot react. Monitoring unfortunately does not have a good reputation. Many IT professionals associate monitoring with added expenses, slower systems and constant, extensive maintenance. However, that comes down to the selected system. The system should be simple, efficient and suitable for the company, should support the IT department and check the right things.
Thank you for the interview!
Mathias’ recommended links
n-Tier Architecture: IT as an onion. „Video for Kids“, but still more interesting than many professional videos
AWS Console breach leads to demise of service with „proven" backup plan: Interesting article about the dangers of the cloud by ars technica.
How to handle downtime duringe site maintenance: Good blog entry about what one can do about short, scheduled downtimes.

Guidelines for IT-failure
How to communicate with customers
Even with a comprehensive monitoring solution, failures can never be eliminated completely. But they don’t have to turn into catastrophes, as the startup examples show (see below) . Frustrated customers that complain during a failure are not necessarily lost for good.
Customers are only then lost when they have the feeling that the company is not interested in them or their needs. To phrase it positively: any company can prove that the customer is important to them in such cases. Ideally, new, strong customer relationships can be formed.
That is why constructing guidelines for dealing with failure situations can be very useful. Here are five questions that should be addressed in every guideline:
1.
Emergency Communication
At least one emergency contact person and a substitute should be specified so that fast reactions are guaranteed even outside of regular working hours or if the contact person is on holidays. IT and monitoring personnel must know who these people are so that they can react quickly.
2.
Channels to be used
If a website is not available, customers search for contact points via other channels. Facebook, Twitter or Google+ can function as these contact points. Accordingly, staff that are responsible for emergency communication require access to social media channels, or need to work together with the responsible personnel in emergency situations.
3.
Transparency!
Objective, transparent communication is important here. The technical problem should be addressed openly and clearly, in a way that is easy for the customer to understand. Underrating the problem or defiant reactions should be avoided completely. It might be a good idea to formulate and agree upon templates for specific failure situations in advance. The templates can be adjusted to fit the specific situation and then released.
4.
Schedule
The faster, the better. Even if the exact problem is not yet known, a short message showing the customer that the problem is being addressed is worthwhile. Share an approximate timeline, if possible. When should the problem be fixed? An hour, or a day? At the same time, acting without thinking is never a good idea. Posting something on Facebook ‘just because’ can backfire.
5.
And afterwards?
A single message doesn’t usually cut it. Users reply fast and often, especially in the social web. Quickly and objectively responding to comments and tips from users is important, as it shows that the customer is being taken seriously despite the failure.


Growing Pains
Startup portals and economics magazines often report on the challenges of startups’ quick growth. Even the Wirtschaftswoche warns, “Start well and don’t grow too quickly.” The business model, products, organization and finance – everything is shaky in the growing phase. “Help, we’re growing!” is on the front page of the Handelsblatt and the article reports on international startup expansion. Bureaucratic hurdles are often underestimated. Company founders reported on their wrong decisions at the Berlin #Failcon. Wrong team, wrong hype, wrong partners – ZDF summarizes their experiences. Hardly anyone mentions the stability of the IT.
A week seldom goes by without reports of fast-growing startups and other young companies struggling with downtime. Here are five recent examples:

A database crashed. For the team, that meant work, work, work, eat pizza and hope. Check out this Tumblr post and this Article by ZDF.
After Facebook purchased Whatsapp, the service Threema doubled its user count within 24 hours. The app was downloaded more than 200,000 times. The sudden change in market created a user rush. Article on Netzwertig.
The taxi service Uber … Uber recently had a huge flood because thousands of taxi drivers demonstrated against the company. Hello, Streisand effect ! Article at wired.com.

The customer support platform GrooveHQ was on its knees for 15 hours. In an emotional blog post, Alex Turnbull, founder, tells about being woken up by a message from his staff: “The app has been offline for 11 hours.” Blogpost at GrooveHQ.

Joel Gascoine from Buffer explains how downtime doesn’t have to be a catastrophe. “Downtime is ultimately an opportunity to make sure that people love you more than they did before.” Here's the article . And the developers from Buffer report on the technical level here

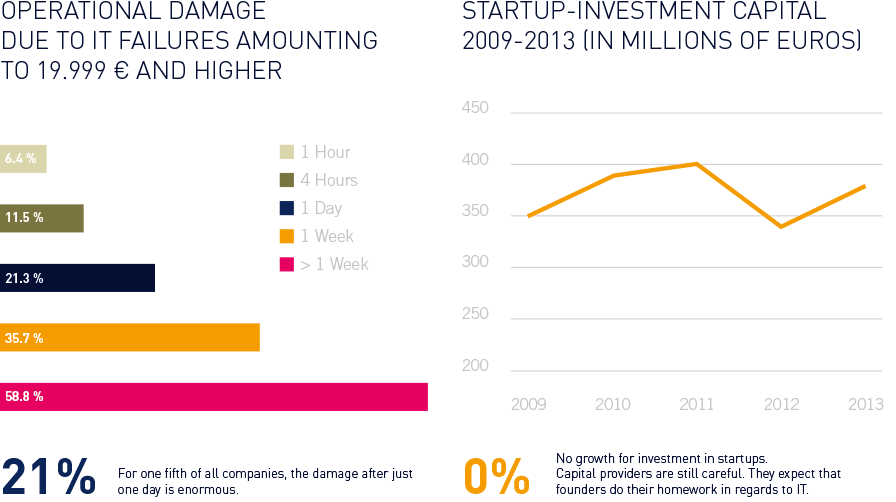
Sources: ECC Köln, BMW, NEG, ibi research, BKV, Total Failure and Errors: Onlineshops 2011

FAQ – The most important questions on IT infrastructure an monitoring
What do online customers expect in 2017 – and what consequences does that have for one’s IT?
High bandwidth has made the Internet fast; surfers’ patience has reduced drastically. Every founder knows that, but most have other things on their minds, like finances, organization and marketing. But availability is a key factor. If the user has to wait even a few seconds longer than his tolerance limit, he’s usually lost – he clicks somewhere else. For startups, this means ensure high performance and keep an eye on the website. Web servers must have enough resources available and lines must provide the necessary bandwidth. Node points like switches, routers or firewalls must not block or slow down data, but still have to guarantee the necessary security. And, of course, the website itself has to work. Content has to be checked, load times need to be watched and shop functions must be guaranteed.
What else could be slowing down web presence?
Web servers require memory and CPU performance. If these are not adequate, the web server cannot execute its tasks sufficiently and website performance drops. Besides monitoring hardware (memory, CPU, network cards, etc.), the monitoring solution has to be able to monitor virtualized environments to guarantee adequate resources for the web server. Sufficient bandwidth is another important requirement for delay-free website delivery. Bandwidth monitoring occurs via various protocols according to the hardware used. Ideally, the selected monitoring solution should support all common bandwidth protocols: SNMP, Flow, Packet Sniffing. Only then can a new switch or an additional firewall be integrated smoothly into the monitoring without requiring additional monitoring solutions or even a complete migration.

Many startups roll out their international services prematurely. What effect does that have on the server?
Many web presences are international but are hosted centrally. This raises the question whether the pages can deliver adequate reaction times internationally as well. To test this, queries must be sent from international locations. Ideally, the monitoring solution can gather data from various locations and send it to the central instance – it doesn’t make sense to work with multiple monitoring tools. This means, for example, that inexpensive server locations can be rented in the most important markets and the centrally hosted website can be monitored from there in order to react quickly to bottlenecks.
Many marketing departments use Google Analytics. Does that conflict with monitoring software for hardware and servers?
Google is the gauge of the Internet and Google Analytics is the tape measure for one’s own web presence. If using a Google Analytics account, it would be useful to incorporate it into the monitoring. Values from Google Analytics could then be used as a foundation for notifications and reports. If supported by the monitoring solution, they can be displayed automatically in overview maps, providing constant, easy access and a clear overview of the values - your marketing team will thank you.
How important is the complete network?
Web servers are located in the server rack in the computing center or at the host – but they are always part of the network and are dependent on the general performance of the network. Consequently, it makes sense to keep an eye on, or monitor, the entire network. This should be taken into consideration when selecting a monitoring tool. It is ultimately counterproductive to use a different monitoring solution for every aspect of the IT. At some point, monitoring the IT will be more laborious than the IT itself. A ‘good’ monitoring tool should reduce the administrator’s work instead of increasing the workload.
All monitoring solution providers compete for the buyer’s favor. At first glance, every solution can do everything. But what should the ‘right’ solution monitor – and how?
Many monitoring solution offer a ping query as a standard web server monitoring tool. But a ping only determines whether the web server is available or not. This is a good beginning, but is nowhere near enough. A suitable monitoring solution should offer options for monitoring websites and their contents in addition to monitoring diverse basic web server parameters: access, data transfer, speed, and even complex queries like checking the time it takes to download a complete website with all content – it doesn’t count for much if a user sees the structure of the website right away but the content doesn’t follow. It should also be possible to query website information in order to keep an eye on changes. Another desirable option is executing transactions on websites. Filling out a form or the process of purchasing something in a shop are not necessarily possible just because the web server reacts to a ping. Some monitoring solutions support so-called Webhooks and can determine if a new comment was written on a blog entry, for example – and, of course, provide the appropriate notifications.
And Now ... Where's the beef?
Take a look at this attractive manual to find out how to monitor your website with monitoring freeware in five easy steps.
Your startup is growing – why you can’t neglect the IT